- Published on
论文分享《Agent Planning with World Knowledge Model》
- Authors

- Name
- McDaddy(戣蓦)
背景与问题
核心问题
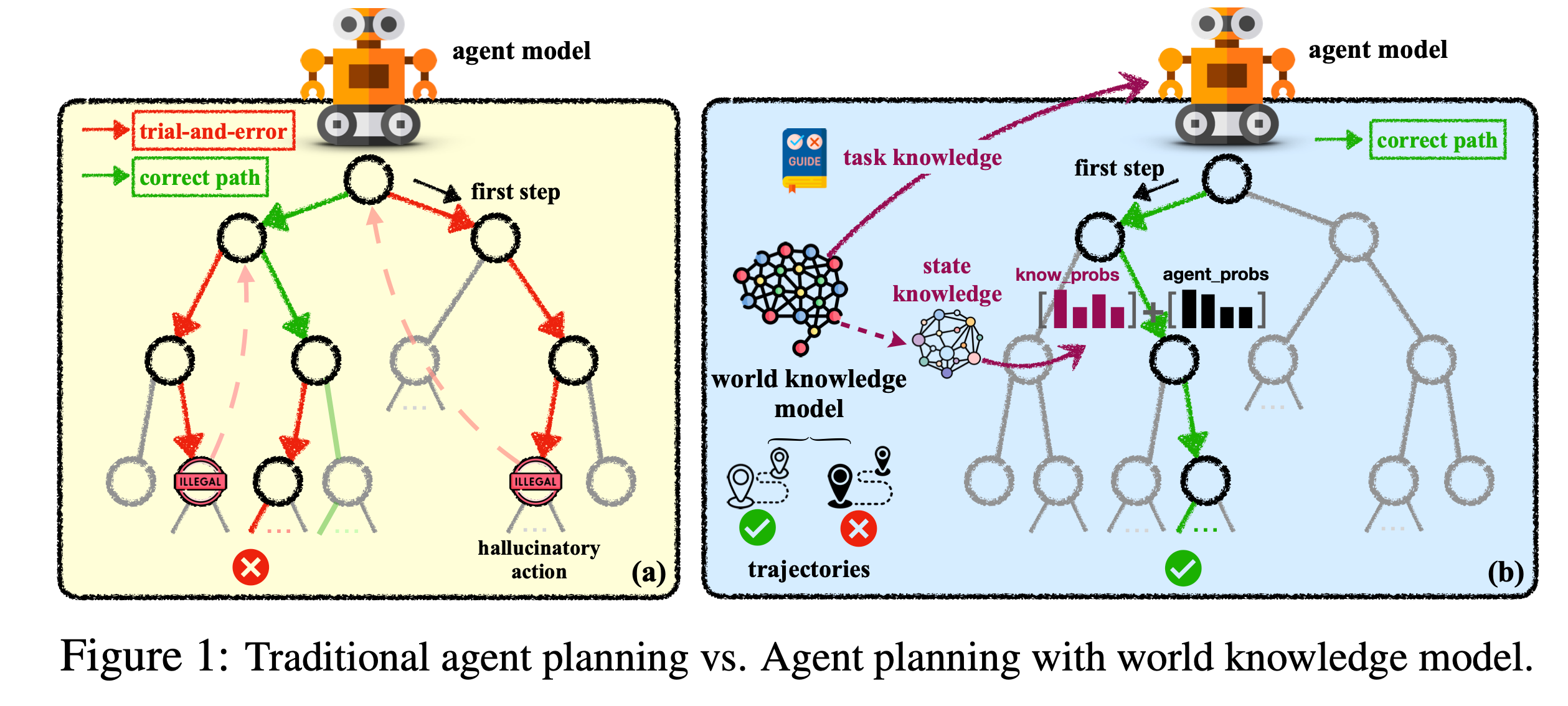
大语言模型(LLMs)在交互式规划任务中表现出显著不足,如全局规划中的盲目试错(缺乏先验任务知识)和局部规划中的幻觉行动(缺乏动态状态认知)。传统方法依赖静态数据或手动设计知识,难以泛化到复杂环境。
灵感与目标
模仿人类的 “心理世界知识模型”,提出参数化世界知识模型(WKM),通过融合先验任务知识(全局规划指导 Task Knowledge)和动态状态知识(局部行动约束 State Knowledge),提升AI Agent的规划能力。
实现方法
目标定义
上面的任务可以表述为部分可观测的交互式任务,那么这里要解的核心问题,其实就是一个部分可观测的马尔科夫决策过程问题(Partially Observable Markov Decision Process)。
主要名词定义
- u: 代表任务和任务的说明及规则
- s:代表当前所处的状态
- a:代表所有可能执行的操作
- o:代表对环境观测的结果
- h:代表执行轨迹,某一个时刻的历史轨迹信息我们可以定义为
ht = (u, a0, o0, a1, o1, . . . , at, ot) - T:代表状态转移方程,即 s * a => s'
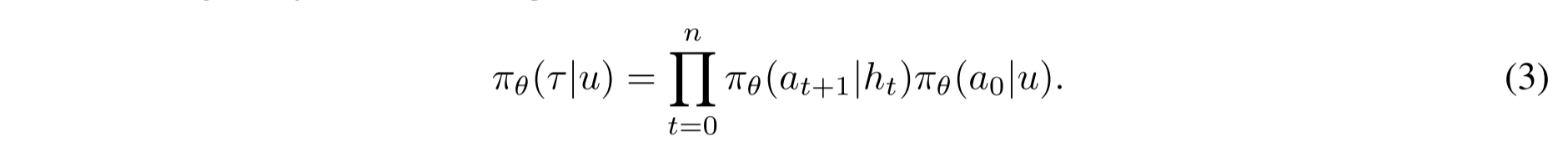
上面的公式表示,在Agent给定任务u的前提下,得到转移方程T的概率
我们的最终目标是使得 reward r(u, T ) 的结果最大化,所以换言之就是通过调整 θ 来实现结果最大化
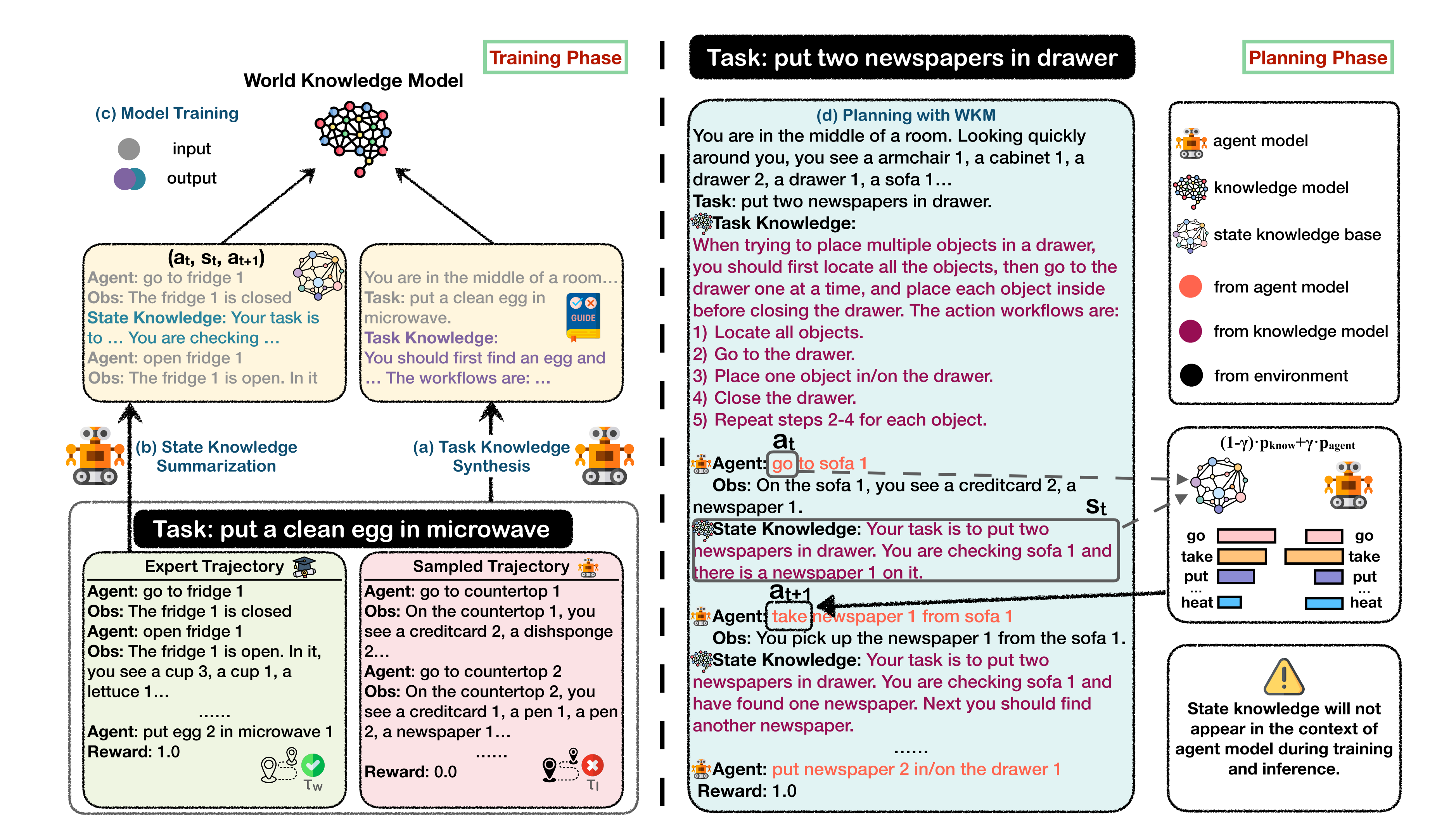
任务知识合成(Task Knowledge Synthesis)
经验Agent探索
- 首先用专家轨迹(Training Set)训练一个基础语言模型,得到 “Experienced Agent”
- Experienced Agent在训练集任务中探索,生成拒绝轨迹(失败或低效轨迹),与专家轨迹(成功轨迹)形成对比。
- 这个对比的目的是为了实现分析得出什么是影响路径成功判断的核心因素,并把它重点呈现出来
自我知识合成: 通过提示(Prompt)引导Agent模型对比专家轨迹和拒绝轨迹,生成任务知识。
提示格式:要求模型总结成功轨迹的关键步骤和策略,例如 “当任务是 X 时,应先做 A,再做 B...”。
公式化:


状态知识总结与知识库构建(State Knowledge Summarization)
状态知识生成: 基于专家轨迹的历史行为(动作 - 观察序列),提示模型生成当前任务状态的总结性知识,例如 “当前任务是清洁肥皂并放入橱柜,已找到肥皂,下一步需清洁”。
- 提示格式:要求模型根据轨迹片段生成简洁的状态描述,如 “State Knowledge: 你的任务是 X,当前已完成 Y,下一步应 Z...”。

- 状态知识库构建: 将状态知识(s_t)与前后动作组合为三元组((a_t, s_t, a_t+1)),构建状态知识库 B。通过检索,利用语义相似性匹配当前状态,约束下一步动作。注意:这里并不是把总结出来的状态知识直接放到LLM的上下文中,而是一个外挂一样的存在
模型训练(Model Training)
Agent Model:
输入:任务指令u + 任务知识k + 专家轨迹tw
损失函数:自回归损失,聚焦动作生成,掩码无关令牌:

WKM:
输入:任务指令u + 任务知识k + 含状态知识的专家轨迹tw(包含(s_t))。
损失函数:联合优化任务知识生成和状态知识匹配,掩码状态相关令牌:
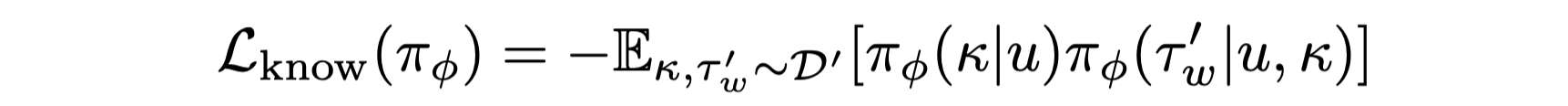
两个模型训练都是使用同样的底层模型(比如Mistral-7B),利用LoRA做微调训练,两者的区别就是WKM多了state knowledge,而损失函数的核心,都是去计算结果与专家轨迹tw的差值和
推理阶段:基于 WKM 的规划(Agent Planning with WKM)
任务知识引导全局规划: WKM 首先生成任务知识k,作为Agent模型的初始指导,例如 “清洁并放置物品时,应先定位物体,再清洁,最后放置”。
状态知识约束局部动作:
生成当前状态信息(s_t),从状态知识库 B 中检索与(a_t)(前一动作)匹配的三元组,获取候选下一动作(a_next)的概率分布(P_know)
Agent模型生成动作概率分布(P_agent)
加权融合两者:

其中γ 为超参数(如 ALFWorld 设 0.4,平衡模型生成与知识库约束)。
注意:在推理阶段WKM的temperature被设置为0,Agent Model为0.5。γ 的取值代表了人为对Task Knowledge和State Knowledge Planning的偏好。 如果γ 为0,则完全信任状态知识库,为1时则完全信任Agent模型
实验与结果
数据集:
ALFWorld(家庭环境交互,二进制奖励)、WebShop(电商场景,密集奖励)、ScienceWorld(科学推理,密集奖励),包含可见 / 不可见任务。
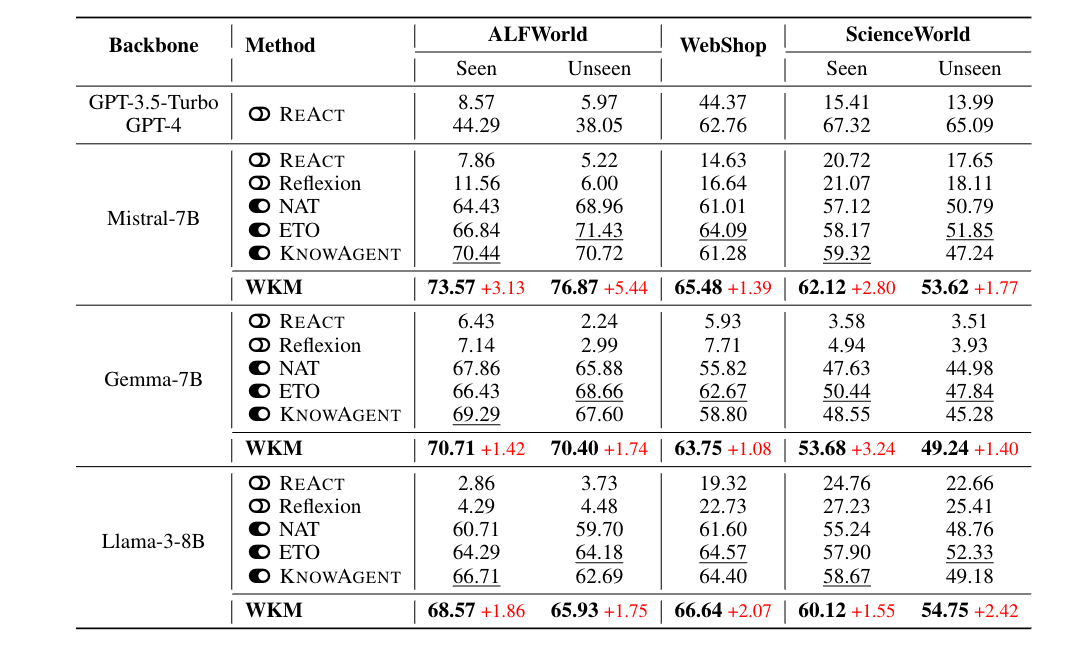
基线方法: REACT、Reflexion(提示基线),NAT、ETO(含拒绝轨迹的微调基线),KNOWAGENT(知识增强基线),以及 GPT-3.5/4。
关键结果:
- 成功率优势
- WKM 在所有数据集上超越强基线,例如在 ALFWorld 可见任务中,Mistral-7B 模型成功率从 ETO 的 66.84% 提升至 73.57%,不可见任务从 71.43% 提升至 76.87%。
- 弱模型(Mistral-7B)生成的任务知识可提升强模型(GPT-4)性能,验证 “弱导强” 范式可行性。
- 消融实验
- 任务知识对不可见任务泛化至关重要,状态知识有效减少幻觉行动(ALFWorld 幻觉率从 ETO 的 36.57% 降至 29.85%)。
- 显式状态知识直接输入会降低性能,验证隐式知识库检索的合理性。
- 效率提升
- WKM 通过减少无效步骤(平均规划步骤比基线少 20%-30%),提升规划效率,且多任务统一训练进一步增强泛化能力。
局限与未来方向
局限:
- 对LLM目前的能力边界到底在哪里还不清楚(这个问题可能还是需要强化学习来解)
- 依赖文本知识,未涉及多模态(如图像、语音)
- 状态知识库基于训练集,动态更新能力不足
- 推理时增加 2.5 倍时间开销
未来方向:
- 构建多模态 WKM
- 结合实时环境反馈动态更新知识库
- 探索统一世界知识模型与代理模型的 AGI 路径。
启发与思考
- 在Oncall、OS排障、调优等场景,当前不论是通过代码框架编排还是通过Aily、Coze等可视化工具编排,都是属于偏静态的设计。这就导致在泛化能力这块会比较弱。所以在条件允许,且专家经验SOP足够积累时,可以适当考虑通过微调模型来实现泛化能力的增强
- 在一些关键节点,比如意图识别、工具选择等行动路径判断节点,可以尝试类似的方法,提升路径选择的准确率